Why Veeksha?¶
Most of today’s LLM system benchmarking tools essentially measure how fast a server can process requests. But users don’t send isolated requests, they have conversations, thinking before typing. They might not even be users, but agents with complex workflows. Conversations (sessions), then, have structure. When measuring inference performance, all aspects of a system’s behavior must be covered. For this, workloads must cover all cases, from extremely synthetic to extremely realistic.
From isolated requests to complex agentic sessions, Veeksha captures the full complexity of modern LLM workloads.
Feature-complete request benchmarking is Veeksha’s baseline, but it is designed to go much further.
Session graphs: beyond linear conversations¶
Most benchmarking tools model multi-turn conversations (if they even support them) as a linear sequence: Turn 1 -> Turn 2 -> Turn 3. Each turn waits for the previous one to complete before starting.
This works for simple chatbots, but modern LLM applications are more complex:
Parallel tool calls: An agent needs to query a database and search the web simultaneously, then combine the results
Branching: A user asks for two different draft responses to compare
Map-reduce patterns: Process multiple chunks in parallel, then aggregate
A linear “list of turns” cannot express “wait for both Tool A and Tool B, then continue.”
Veeksha’s approach: Sessions are modeled as directed acyclic graphs (DAGs). Each node is a request, and edges define dependencies. Nodes with no unfinished dependencies can execute in parallel.

A linear session: requests execute sequentially with dependencies.¶
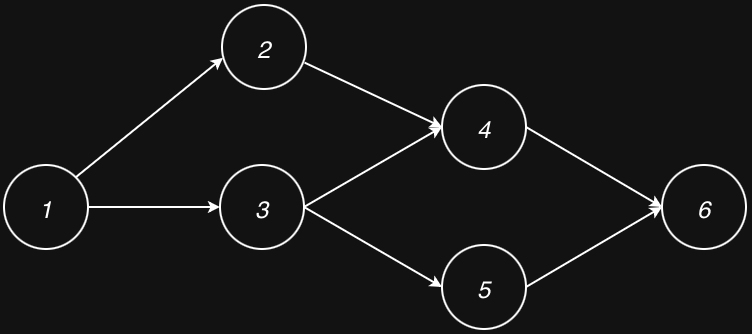
A DAG session: parallel branches with synchronization points.¶
Explicit history inheritance: In multi-turn conversations, later turns typically include the full conversation history. But some workflows are more nuanced. A request might depend on a parent’s timing (wait for it to complete) but either:
Start a fresh context (no history inheritance)
Inherit history from a specific ancestor
Veeksha makes this explicit with the is_history_parent flag on edges, giving
you precise control over what context each request receives.
Flexible traffic scheduling¶
Veeksha supports two fundamentally different session traffic models:
- Rate-based (open-loop)
Sessions arrive according to a configurable distribution (Poisson, gamma, or fixed interval), independent of whether previous sessions have completed. This reveals true tail latency under burst traffic because the load generator doesn’t throttle itself when the server slows down.
- Concurrency-based (closed-loop)
Maintains a target number of active sessions. When one completes, another starts. Useful for stress testing and finding maximum throughput under sustained load.
Both modes can be combined with any workload type.
Think time: user simulation, not rate limiting¶
Some benchmarks add a “sleep” after sending a request to throttle the load. But there’s a crucial difference between:
Rate limiting: Sleep after the request to control how fast the load generator sends requests
Think time: Sleep after the response to model how long a user takes to read and type their next message
Why does this matter? Consider prefix caching. If your LLM server caches the conversation history (the “prefix”), that cache might expire while the user is reading a long response. A benchmark that sleeps after sending doesn’t test this scenario. A benchmark that sleeps after receiving (modeling think time) reveals whether your cache survives realistic user pauses.
Veeksha’s approach: Each node in the session graph has a configurable
wait_after_ready delay that fires after its dependencies complete, modeling
the user reading the response before continuing.
Trace flavors for real workloads¶
Many benchmarks treat all traces the same way. Veeksha introduces trace flavors that define how to parse and replay different trace types (coding assistants, RAG, conversational datasets), each with appropriate wrapping and shuffling behavior. See Trace Flavors for a practical guide to choosing a flavor and formatting the trace.
Multimodal architecture¶
Veeksha’s content generation uses a channel-based architecture (text, image, audio, video). Text is fully implemented today, with the architecture ready for multimodal workloads. See Content Generation for details.
Composable evaluation¶
Veeksha is more than a workload generator:
Combine workloads with evaluators: Run accuracy evaluation (via lm-eval-harness integration) under different load levels to see how model quality degrades as the system saturates.
SLO checking: Easily define service level objectives for metrics such as TPOT, TBC, TTFC, or end to end latency and check compliance under different workloads. For example, “90% of requests must have a TTFC smaller than 0.5 seconds.”
Capacity search: Automatically find the maximum sustainable session rate or concurrency that meets your SLOs using an adaptive probe-then-binary-search algorithm.
Microbenchmarks: Isolate specific operations (prefill vs. decode) for targeted performance measurement with decode window analysis.
Veeksha scales down too!¶
Veeksha doesn’t force you to just model complex sessions. A session can contain a single request, which makes Veeksha behave like a traditional request dispatcher:

Single-request sessions: all requests are independent, equivalent to traditional load generators.¶
The key insight is that Veeksha handles inter-session scheduling asynchronously (sessions arrive according to your traffic model) while handling intra-session dependencies synchronously (requests within a session respect their graph structure).
This means you can:
Blast the server with independent requests (sessions of size 1)
Simulate multi-turn conversations (linear sessions)
Model agentic workflows (DAG sessions)
And because you also control the traffic model, you can construct any benchmark you might need. All with the same tool, the same configuration format, and the same evaluation pipeline.
When to use Veeksha¶
Veeksha is designed for teams who need to evaluate LLM inference systems across the whole range of use cases. If you need to understand your system’s capacity, benchmark agentic support at scale, understand tail effects under bursty traffic, test prefix caching and production readiness, model accuracy under load, or more, we believe Veeksha can help.
Next steps¶
Installation - Get started with Veeksha
Sessions and Graphs - Deep dive into the session graph model
Traffic Scheduling - Understand traffic scheduling in detail
Quick start - Run your first benchmark